Repositório de Word Embeddings do NILC
NILC - Núcleo Interinstitucional de Linguística Computacional
Introdução
NILC-Embeddings é um repositório destinado ao armazenamento e compartilhamento de vetores de palavras (do inglês, word embeddings) gerados para a Língua Portuguesa. O objetivo é fomentar e tornar acessível recursos vetoriais prontos para serem utilizados nas tarefas de Processamento da Linguagem Natural e Aprendizado de Máquina. O repositório traz vetores gerados a partir de um grande córpus do português do Brasil e português europeu, de fontes e gêneros variados. Foram utilizados dezessete córpus diferentes, totalizando 1,395,926,282 tokens. O treinamento dos vetores ocorreu em algoritmos como Word2vec [1], FastText [2], Wang2vec [3] e Glove [4]. Mais detalhes sobre o projeto podem ser encontrados em: Portuguese Word Embeddings: Evaluating on Word Analogies and Natural Language Tasks.
Córpus utilizado
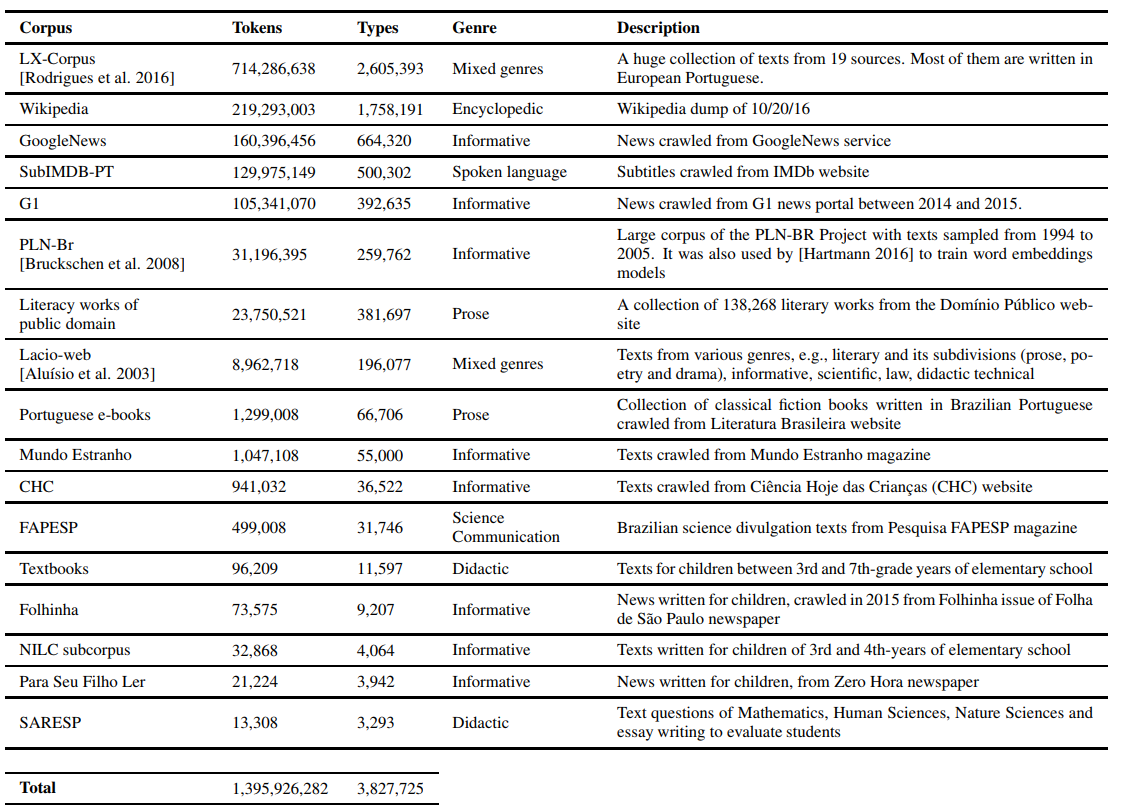
A seguir, são apresentadas as fontes do córpus (imagem retirada da Tabela 1. Sources and statistics of corpora collected do artigo).
A parcela pública do córpus (tudo exceto o LX-Corpus) está disponível para download.
Artigo produzido
Esse trabalho produziu um artigo aceito para publicação no STIL 2017 -- Symposium in Information and Human Language Technology. Os anais do evento estão disponíveis aqui. A versão preprint do artigo pode ser visto aqui.
Download Scripts Pré-processamento e Scripts de Avaliação
Os scripts utilizados para pré-processamento dos dados, bem como os scripts para as avaliações realizadas, estão disponíveis para download.
Download Word Embeddings Pré-treinadas
Para cada modelo, foram disponibilizados vetores de palavras gerados em várias dimensões. Alguns modelos como Word2vec, FastText e Wang2vec possuem as variações CBOW e Skip-Gram, que diferenciam-se pela forma como preveem as palavras. Em "Ver Detalhes" pode-se ter acesso à rotinas de pré-processamento, limpeza e avaliação. No córpus, foram feitas tratativas de tokenização, remoção de stopwords, stemmização e outras.
Word2Vec
| Modelo | Corpora STIL 2017 | |||
| CBOW 50 dimensões | download | |||
| CBOW 100 dimensões | download | |||
| CBOW 300 dimensões | download | |||
| CBOW 600 dimensões | download | |||
| CBOW 1000 dimensões | download | |||
| SKIP-GRAM 50 dimensões | download | |||
| SKIP-GRAM 100 dimensões | download | |||
| SKIP-GRAM 300 dimensões | download | |||
| SKIP-GRAM 600 dimensões | download | |||
| SKIP-GRAM 1000 dimensões | download | |||
FastText
| Modelo | Corpora STIL 2017 | |||
| CBOW 50 dimensões | download | |||
| CBOW 100 dimensões | download | |||
| CBOW 300 dimensões | download | |||
| CBOW 600 dimensões | download | |||
| CBOW 1000 dimensões | download | |||
| SKIP-GRAM 50 dimensões | download | |||
| SKIP-GRAM 100 dimensões | download | |||
| SKIP-GRAM 300 dimensões | download | |||
| SKIP-GRAM 600 dimensões | download | |||
| SKIP-GRAM 1000 dimensões | download | |||
Wang2Vec
| Modelo | Corpora STIL 2017 | |||
| CBOW 50 dimensões | download | |||
| CBOW 100 dimensões | download | |||
| CBOW 300 dimensões | download | |||
| CBOW 600 dimensões | download | |||
| CBOW 1000 dimensões | download | |||
| SKIP-GRAM 50 dimensões | download | |||
| SKIP-GRAM 100 dimensões | download | |||
| SKIP-GRAM 300 dimensões | download | |||
| SKIP-GRAM 600 dimensões | download | |||
| SKIP-GRAM 1000 dimensões | download | |||
Glove
| Modelo | Corpora STIL 2017 | |||
| GLOVE 50 dimensões | download | |||
| GLOVE 100 dimensões | download | |||
| GLOVE 300 dimensões | download | |||
| GLOVE 600 dimensões | download | |||
| GLOVE 1000 dimensões | download | |||
Como Utilizar
Agora os modelos estão corrigidos para serem carregados somente utilizando o KeyedVectors do gensim.| Instalar | |
| pip install gensim==4.3.1 #última versão validada mas deve funcionar com versões mais recentes...seguimos acompanhando | |
| Rodar | |
| from gensim.models import KeyedVectors | |
| model = KeyedVectors.load_word2vec_format(‘model.txt’) |
Referências
[1] Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013). Efficient estimation of word representations in vector space. In Proceedings of International Conference on Learning Representations Workshop (ICLR-2013).
[2] Bojanowski, P., Grave, E., Joulin, A., and Mikolov, T. (2016). Enriching Word Vectors with Subword Information. arXiv preprint arXiv:1607.04606.
[3] Ling, W., Dyer, C., Black, A., and Trancoso, I. (2015). Two/too simple adaptations of word2vec for syntax problems. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics.
[4] Pennington, J., Socher, R., and Manning, C. D. (2014). Glove: Global vectors for word representation. Proceedings of the 2014 Conference on Empiricial Methods in Natural Language Processing (EMNLP-2014), 12:1532–1543.


© 2017 NILC - Núcleo Interinstitucional de Linguística Computacional
 This work is licensed under a Creative Commons Attribution 4.0 International License
This work is licensed under a Creative Commons Attribution 4.0 International License