
Reconhecimento Automático de Fala
O que são os reconhecedores de fala?
Os reconhecedores de fala buscam transformar, de forma eficiente e precisa, o sinal acústico da fala em sua contraparte textual (Rabiner & Schafer, 2007). A fala é, indubitavelmente, a forma mais natural e expressiva de comunicação humana. De tal modo, métodos automáticos para reconhecê-la e analisá-la vêm sendo investigados há tempo já considerável, tendo os primeiros sistemas de Reconhecimento Automático de Fala (doravante RAF) sido construídos na década de 50 (Furui, 2005). Atualmente, as aplicações de RAF abrangem os mais diversos domínios, a exemplo de: ferramentas de ditado em editores de texto, serviços de call steering, sistemas hands-free em automóveis, acessibilidade de pessoas com deficiência motora, interface mobile via fala, aplicações de booking em companhias aéreas, sistemas de segurança por identificação de voz, etc.
Reconhecedores de fala são de especial interesse para o desenvolvimento de sistemas de CALL (Computer Assisted Language Learning) voltados ao ensino e à avaliação de pronúncia, os chamados sistemas de CAPT (Computer Assisted Pronunciation Training) (Eskenazi, 2009). O grande desafio da área de CAPT está em manipular e tratar dados de fala de não-nativos.
Os problemas de tratar a fala de não-nativos
Falantes não-nativos impõem um desafio a mais aos sistemas de RAF tradicionais, por adicionarem ainda mais variação e entropia aos dados de entrada. Falantes não-nativos apresentam padrões de pronúncia que destoam do previsto no modelo acústico do reconhecedor, construções sintáticas que não condizem com o modelo de língua elaborado e um léxico reduzido. Além disso, eles não compõem um grupo homogêneo: os padrões são distintos de acordo com a língua nativa que falam, a língua-alvo que buscam aprender e o grau de proficiência que possuem nessa língua-alvo (Compernolle, 2001). Franceses, brasileiros, alemães e chineses, por exemplo, aprenderão inglês de modo diferente, cada um à sua maneira. Caso se tente utilizar um reconhecedor para o inglês nativo com esses falantes, certamente, o desempenho será baixo, tendo em vista que o reconhecedor não estará preparado para os padrões acústico-articulatórios e sentenciais que os não-nativos produzirão.
Os tipos de reconhecedor
Reconhecedores Automáticos de Fala podem ser divididos em três categoriais, que se diferem quanto à tarefa de reconhecimento que desempenham: i) reconhecimento de palavras isoladas; ii) de sentenças pré-estabelecidas; iii) reconhecimento de fala contínuo de grande vocabulário (RFCGV). O Listener emprega reconhecimento nesses três níveis.
Como funciona um reconhecedor?
A grande maioria dos sistemas de RAF baseia-se em modelos estatísticos, especialmente, Modelos Ocultos de Markov, ou Hidden Markov Models (HMM) (Huang, et al., 2001). Em tais modelos, a tarefa de reconhecimento é considerada a partir da metáfora do canal ruidoso, ou noisy-channel (Jurafsky & Martin, 2009). O sinal acústico, que constitui a entrada no sistema, é visto como uma deformação da mensagem original, isto é, da sequência de palavras pretendida pelo falante, após passar por um canal com ruído. Assim, o reconhecimento se torna uma tarefa de decodificação: trata-se de como recuperar a mensagem original a partir do sinal acústico “ruidoso”. Matematicamente, isso corresponde a estimar, considerando-se uma língua L, para uma sequência de palavras W, qual é a sequência Ŵ mais provável, dado conjunto de estados acústicos observáveis O:
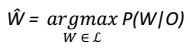
Todavia, não é possível calcular diretamente, sendo necessário aplicar-se o Teorema de Bayes, de modo a obter-se:
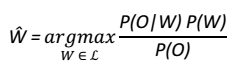
Como a propósito é buscar a sequência de palavras mais provável para um conjunto já dado de estados acústicos, se repete a cada cálculo, de maneira que pode ser considerado uma constante de normalização, e a equação pode ser simplificada para:
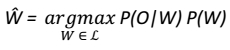
Essa equação fundamenta a base dos sistemas de RAF estocásticos e possui estreita relação com a arquitetura que é por eles compartilhada. Basicamente, os sistemas de RAF contínuo com grande vocabulário possuem três módulos: (i) um modelo de língua, (ii) um modelo acústico e (iii) um modelo, ou dicionário de pronúncia. O modelo de língua é utilizado para estimar , a probabilidade a priori da sequência de palavras. Já o modelo acústico é utilizado para calcular , a verossimilhança da observação. Por fim, o dicionário de pronúncia serve como uma ponte entre o modelo de língua e o modelo acústico, uma vez que possui as palavras que compõem o léxico do reconhecedor, transcritas em forma ortográfica e fonética. A Figura 1 ilustra a arquitetura básica de um sistema de RAF.
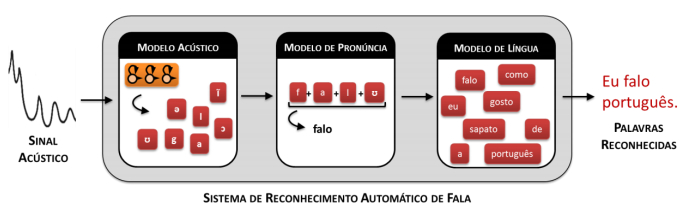
O modelo acústico processa o sinal acústico da fala, de modo a inferir quais são os segmentos sonoros que a compõem, usualmente, empregando fones ou trifones1. Em reconhecedores de base em HMM, essa tarefa é feita estimando-se os estados acústicos observados mais prováveis, bem como suas probabilidades de transição. Já o modelo de pronúncia provê a correspondência entre sequências de fones e as palavras da língua. No exemplo, tal modelo mapeia a sequência de fones [falʊ] na palavra “falo”. O modelo de língua, por sua vez, estima as ordenações de palavras mais prováveis na língua.
Como adaptar um reconhecedor para a fala de não-nativos?
Para fazer com que um reconhecedor de fala se adeque a dados de fala de não-nativos, é necessário modificar cada um dos módulos do reconhecedor. Conforme apontam Strik e Cucchiarini (1999), variações de pronúncia de falantes não-nativos podem ser adicionadas a qualquer nível do reconhecedor: no modelo acústico, no modelo de língua ou no modelo de pronúncia.
Sobre o modelo acústico, três métodos de adaptação têm sido propostos: (i) adaptação ao falante; (ii) construção de modelos bilíngues; e (iii) utilização modelos combinados, ou de interlíngua (Wang et al., 2003). Tais métodos distinguem-se quanto à origem dos dados acústicos utilizados para treinar o modelo. Na adaptação ao falante, são utilizados apenas dados de fala de falantes nativos da língua alvo. Na construção de modelos bilíngues, empregam-se no treinamento do modelo acústico dados de fala de falantes nativos tanto da língua alvo, quanto da língua base. Por fim, nos modelos combinados, ou de interlíngua, o modelo acústico é treinado tendo em vista dados de falantes nativos da língua alvo e, também, de aprendizes. A Figura 2 resume as três abordagens disponíveis para adaptar o modelo acústico de um sistema de RAF.
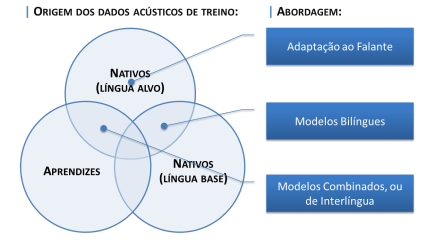
Diversos métodos e algoritmos podem ser empregados para realizar uma das três abordagens de adaptação, a exemplo de: MLLR + MAP + Identificação de fones mais informativos (Oh et al., 2006), Phonetic Decision Tree (PDT) (Chen & Cheng, 2012), Polyphone Decision Tree Specialization (PDTS) (Wang et al., 2003), Eigenvoices + MLLR (Tan & Besacier, 2007), Phoneset comum + Modelo multilíngue (Fischer et al., 2002).
Sobre o dicionário de pronúncia, a adaptação que se costuma fazer ao dicionário de pronúncia é a adição das formas variantes de pronúncia do não-nativo, de modo a construir os chamados dicionários multipronúncia. A Figura 3 ilustra a inserção de possíveis formas variantes de pronúncia da palavra "disappear", por um aprendiz:
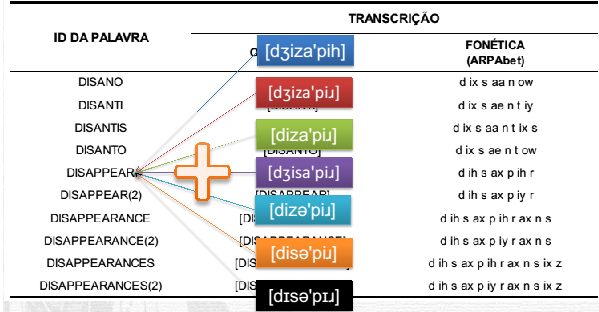
A construção de tais dicionários pode se dar por meio de duas abordagens: (i) baseada em conhecimento ou (ii) baseada em dados (Strik & Cucchiarini, 1999).Na abordagem baseada em conhecimento, variantes de pronúncia são inseridas no dicionário do reconhecedor por meio de regras geradas por um especialista – um linguista, que busca explicitar os padrões de pronúncia que subjaz à língua. Já a abordagem baseada em dados para a construção de dicionários multipronúncia pode ser classificada como direta ou indireta (Kim, Oh, & Kiem, 2007). Na direta, padrões de variação existentes em um conjunto de teste são analisados e utilizados, imediatamente, para gerar as palavras variantes. Já na indireta, busca-se inferir regras que possam ser aplicadas na geração de uma ou mais variantes para uma palavra.
Diversas técnicas podem ser utilizadas para elaborar um dicionário multipronúncia, a exemplo de: Gaussian Densities Across Phonetic Models (Saraçlar & Khudanpur, 2000), Group Delay Based Segmentation (Brunet & Murthy, 2012), Phones Adaptation and Pronunciation Generalization (Ahmed & Ping, 2011), Automatic Generation of Accented Variants + MLLR (Goronzy & Eisele, 2003), Multi-span Linguistic Parse Tables (Mertens et al., 2011), Decision Trees (Byrne et al., 1998), Pronunciation Mixture Model (McGraw et al., 2008).
Sobre o modelo de língua, é possível estimá-lo através da utilização de textos que melhor condigam com os padrões sintáticos do aprendiz. Pode-se, por exemplo, utilizar textos escritos por aprendizes, ou textos escritos de modo a apresentar uma sintaxe mais simples, como a Simple English Wikipedia.